
版本向量(Version Vector)
原文
https://martinfowler.com/articles/patterns-of-distributed-systems/version-vector.html
集群中的每个节点各自维护一组计算器,以检查并发的更新。
2021.6.29
问题
如果允许多个服务器对同样的键值进行更新,那么有值在一组副本中并发地更新就显得非常重要了。
解决方案
每个键值都同一个版本向量关联在一起,版本向量为集群的每个节点维护一个数字。
从本质上说,版本向量就是一组计数器,每个节点一个。三节点(blue, green, black)的版本向量可能看上去是这样:[blue: 43, green: 54, black: 12]。每次一个节点有内部更新,它都会更新它自己的计数器,因此,green 节点有更新,就会将版本向量修改为[blue: 43, green: 55, black: 12]。两个节点通信时,它们会同步彼此的向量时间戳,这样就检测出任何同步的更新。
一个典型的版本向量实现是下面这样:
class VersionVector…
private final TreeMap<String, Long> versions;
public VersionVector() {
this(new TreeMap<>());
}
public VersionVector(TreeMap<String, Long> versions) {
this.versions = versions;
}
public VersionVector increment(String nodeId) {
TreeMap<String, Long> versions = new TreeMap<>();
versions.putAll(this.versions);
Long version = versions.get(nodeId);
if(version == null) {
version = 1L;
} else {
version = version + 1L;
}
versions.put(nodeId, version);
return new VersionVector(versions);
}存储在服务器上的每个值都关联着一个版本向量
class VersionedValue…
public class VersionedValue {
String value;
VersionVector versionVector;
public VersionedValue(String value, VersionVector versionVector) {
this.value = value;
this.versionVector = versionVector;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
VersionedValue that = (VersionedValue) o;
return Objects.equal(value, that.value) && Objects.equal(versionVector, that.versionVector);
}
@Override
public int hashCode() {
return Objects.hashCode(value, versionVector);
}比较版本向量
版本向量是通过比较每个节点的版本号进行比较的。如果两个版本向量中都拥有相同节点的版本号,而且其中一个的版本号都比另一个高,则认为这个版本向量高于另一个,反之亦然。如果两个版本向量并不是都高于另一个,或是对于拥有不同集群节点的版本号,则二者可以并存。
下面是一些比较的样例。
{blue:2, green:1} | 大于 | {blue:1, green:1} |
{blue:2, green:1} | 并存 | {blue:1, green:2} |
{blue:1, green:1, red: 1} | 大于 | {blue:1, green:1} |
{blue:1, green:1, red: 1} | 并存 | {blue:1, green:1, pink: 1} |
比较的实现如下:
public enum Ordering {
Before,
After,
Concurrent
}
class VersionVector…
//This is exact code for Voldermort implementation of VectorClock comparison.
//https://github.com/voldemort/voldemort/blob/master/src/java/voldemort/versioning/VectorClockUtils.java
public static Ordering compare(VersionVector v1, VersionVector v2) {
if(v1 == null || v2 == null)
throw new IllegalArgumentException("Can't compare null vector clocks!");
// We do two checks: v1 <= v2 and v2 <= v1 if both are true then
boolean v1Bigger = false;
boolean v2Bigger = false;
SortedSet<String> v1Nodes = v1.getVersions().navigableKeySet();
SortedSet<String> v2Nodes = v2.getVersions().navigableKeySet();
SortedSet<String> commonNodes = getCommonNodes(v1Nodes, v2Nodes);
// if v1 has more nodes than common nodes
// v1 has clocks that v2 does not
if(v1Nodes.size() > commonNodes.size()) {
v1Bigger = true;
}
// if v2 has more nodes than common nodes
// v2 has clocks that v1 does not
if(v2Nodes.size() > commonNodes.size()) {
v2Bigger = true;
}
// compare the common parts
for(String nodeId: commonNodes) {
// no need to compare more
if(v1Bigger && v2Bigger) {
break;
}
long v1Version = v1.getVersions().get(nodeId);
long v2Version = v2.getVersions().get(nodeId);
if(v1Version > v2Version) {
v1Bigger = true;
} else if(v1Version < v2Version) {
v2Bigger = true;
}
}
/*
* This is the case where they are equal. Consciously return BEFORE, so
* that the we would throw back an ObsoleteVersionException for online
* writes with the same clock.
*/
if(!v1Bigger && !v2Bigger)
return Ordering.Before;
/* This is the case where v1 is a successor clock to v2 */
else if(v1Bigger && !v2Bigger)
return Ordering.After;
/* This is the case where v2 is a successor clock to v1 */
else if(!v1Bigger && v2Bigger)
return Ordering.Before;
/* This is the case where both clocks are parallel to one another */
else
return Ordering.Concurrent;
}
private static SortedSet<String> getCommonNodes(SortedSet<String> v1Nodes, SortedSet<String> v2Nodes) {
// get clocks(nodeIds) that both v1 and v2 has
SortedSet<String> commonNodes = Sets.newTreeSet(v1Nodes);
commonNodes.retainAll(v2Nodes);
return commonNodes;
}
public boolean descents(VersionVector other) {
return other.compareTo(this) == Ordering.Before;
}在键值存储中使用版本向量
在键值存储中,可以像下面这样使用版本向量。这里需要一组有版本的值,这样就可以有多个并发的值了。
class VersionVectorKVStore…
public class VersionVectorKVStore {
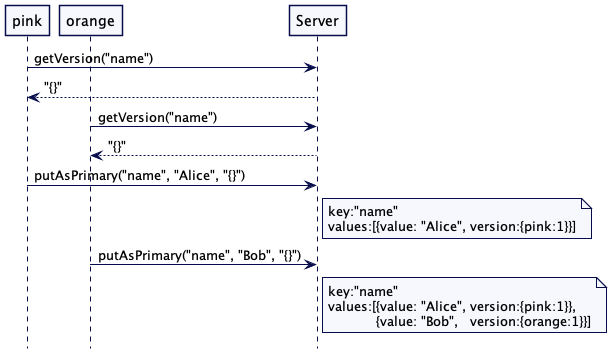
Map<String, List<VersionedValue>> kv = new HashMap<>();当客户端要存储一个值时,它先用给定的键值读取到最新的已知版本。然后,根据键值选择集群的一个节点进行值的存储,这时客户端会回传已知的版本。请求流程如下图所示。有两个服务器分别叫 blue 和 green。对于“name”这个键值,green 就是主服务器。
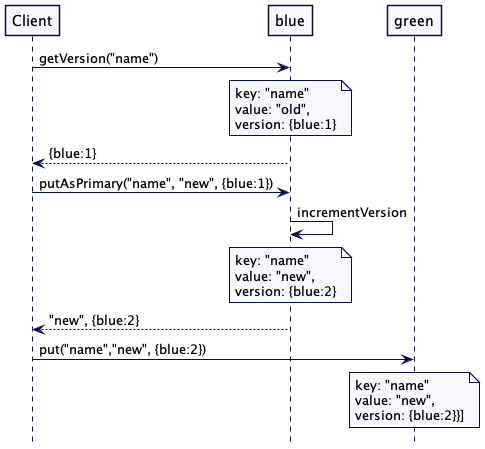
在无领导者复制的模式下,客户端或协调者节点会根据键值选取节点进行数据写入。根据键值所映射的集群主节点,版本向量会进行相应的更新。就复制而言,具有相同版本向量的值就可以复制到其它集群节点上。如果键值对应的集群节点不可用,就选择下一个节点。对于保存值的第一个集群节点而言,版本向量只能递增。所有其它节点保存的只是数据的副本。像 voldemort 这样的数据库,递增版本向量的代码看上去是这样的:
class ClusterClient…
public void put(String key, String value, VersionVector existingVersion) {
List<Integer> allReplicas = findReplicas(key);
int nodeIndex = 0;
List<Exception> failures = new ArrayList<>();
VersionedValue valueWrittenToPrimary = null;
for (; nodeIndex < allReplicas.size(); nodeIndex++) {
try {
ClusterNode node = clusterNodes.get(nodeIndex);
//the node which is the primary holder of the key value is responsible for incrementing version number.
valueWrittenToPrimary = node.putAsPrimary(key, value, existingVersion);
break;
} catch (Exception e) {
//if there is exception writing the value to the node, try other replica.
failures.add(e);
}
}
if (valueWrittenToPrimary == null) {
throw new NotEnoughNodesAvailable("No node succeeded in writing the value.", failures);
}
//Succeded in writing the first node, copy the same to other nodes.
nodeIndex++;
for (; nodeIndex < allReplicas.size(); nodeIndex++) {
ClusterNode node = clusterNodes.get(nodeIndex);
node.put(key, valueWrittenToPrimary);
}
}充当主节点的节点会递增版本号。
public VersionedValue putAsPrimary(String key, String value, VersionVector existingVersion) {
VersionVector newVersion = existingVersion.increment(nodeId);
VersionedValue versionedValue = new VersionedValue(value, newVersion);
put(key, versionedValue);
return versionedValue;
}
public void put(String key, VersionedValue value) {
versionVectorKvStore.put(key, value);
}从上面的代码可以看出,不同的客户端可以在不同的节点上更新相同的键值,比如,当客户端无法触达某个特定节点时。这就会造成一种情况,不同的节点有不同的值,根据它们的版本向量,可以认为这些值是“并发的”。
如下图所示,client1 和 client2 都在尝试写入“name”这个键值。如果 client1 无法写入到 green 这个服务器,green 服务器就会丢掉 client1 写入的值。当 client2 尝试写入但无法连接到 blue 服务器,它就会写入到 green 服务器。“name”这个键值的版本向量就反映出 blue 和 green 两个服务器存在并发写入。
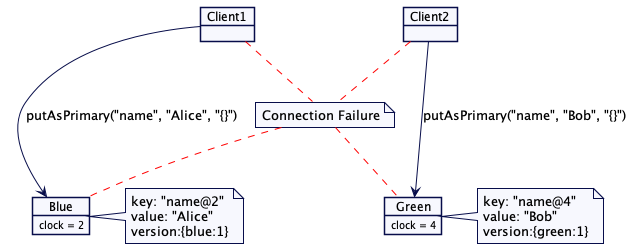
因此,当认为版本是并发的时候,基于存储的版本向量对于任何键值都会持有多个版本。
class VersionVectorKVStore…
public void put(String key, VersionedValue newValue) {
List<VersionedValue> existingValues = kv.get(key);
if (existingValues == null) {
existingValues = new ArrayList<>();
}
rejectIfOldWrite(key, newValue, existingValues);
List<VersionedValue> newValues = merge(newValue, existingValues);
kv.put(key, newValues);
}
//If the newValue is older than existing one reject it.
private void rejectIfOldWrite(String key, VersionedValue newValue, List<VersionedValue> existingValues) {
for (VersionedValue existingValue : existingValues) {
if (existingValue.descendsVersion(newValue)) {
throw new ObsoleteVersionException("Obsolete version for key '" + key
+ "': " + newValue.versionVector);
}
}
}
//Merge new value with existing values. Remove values with lower version than the newValue.
//If the old value is neither before or after (concurrent) with the newValue. It will be preserved
private List<VersionedValue> merge(VersionedValue newValue, List<VersionedValue> existingValues) {
List<VersionedValue> retainedValues = removeOlderVersions(newValue, existingValues);
retainedValues.add(newValue);
return retainedValues;
}
private List<VersionedValue> removeOlderVersions(VersionedValue newValue, List<VersionedValue> existingValues) {
List<VersionedValue> retainedValues = existingValues
.stream()
.filter(v -> !newValue.descendsVersion(v)) //keep versions which are not directly dominated by newValue.
.collect(Collectors.toList());
return retainedValues;
}如果从多个节点中进行读取时,检测到了并发值,就会抛出错误,这就要允许客户端解决冲突了。
解决冲突
如果不同的副本返回了多个版本,向量时钟比较可以检测出最新的值。
class ClusterClient…
public List<VersionedValue> get(String key) {
List<Integer> allReplicas = findReplicas(key);
List<VersionedValue> allValues = new ArrayList<>();
for (Integer index : allReplicas) {
ClusterNode clusterNode = clusterNodes.get(index);
List<VersionedValue> nodeVersions = clusterNode.get(key);
allValues.addAll(nodeVersions);
}
return latestValuesAcrossReplicas(allValues);
}
private List<VersionedValue> latestValuesAcrossReplicas(List<VersionedValue> allValues) {
List<VersionedValue> uniqueValues = removeDuplicates(allValues);
return retainOnlyLatestValues(uniqueValues);
}
private List<VersionedValue> retainOnlyLatestValues(List<VersionedValue> versionedValues) {
for (int i = 0; i < versionedValues.size(); i++) {
VersionedValue v1 = versionedValues.get(i);
versionedValues.removeAll(getPredecessors(v1, versionedValues));
}
return versionedValues;
}
private List<VersionedValue> getPredecessors(VersionedValue v1, List<VersionedValue> versionedValues) {
List<VersionedValue> predecessors = new ArrayList<>();
for (VersionedValue v2 : versionedValues) {
if (!v1.sameVersion(v2) && v1.descendsVersion(v2)) {
predecessors.add(v2);
}
}
return predecessors;
}
private List<VersionedValue> removeDuplicates(List<VersionedValue> allValues) {
return allValues.stream().distinct().collect(Collectors.toList());
}当有并发的更新时,仅仅根据版本向量做冲突解决是不够的。因此,很重要的一点是,由客户端提供应用特定的冲突解决器(Conflict Resolver)。客户端在读取值的时候提供一个冲突解决器。
public interface ConflictResolver {
VersionedValue resolve(List<VersionedValue> values);
}
class ClusterClient…
public VersionedValue getResolvedValue(String key, ConflictResolver resolver) {
List<VersionedValue> versionedValues = get(key);
return resolver.resolve(versionedValues);
}比如,riak就允许提供冲突解决器,就像这里解释的那样。
最后写入胜(Last Write Wins, LWW)的冲突解决
虽然版本向量允许检测不同服务器组的并发写入,但在产生冲突的情况下,其本身并不能帮助给客户端提供识别出选择哪个值。解决问题的责任在客户端身上。有时,客户端倾向于让键值存储根据时间戳来解决冲突。虽然通过跨服务器的时间戳存在一些已知的问题,但这种方式胜在简单,使其成为了客户端的首选方案,即便是由于跨服务器时间戳的问题,存在丢失一些更新的风险。它们完全要依赖于像 NTP 这样的服务得到良好的配置,能够跨集群工作正常。像 riak 和 voldemort 这样的数据库允许用户选择“最后写入胜”的冲突解决策略。
要支持 LWW 冲突解决,每个值写入时就要带上时间戳。
class TimestampedVersionedValue…
class TimestampedVersionedValue {
String value;
VersionVector versionVector;
long timestamp;
public TimestampedVersionedValue(String value, VersionVector versionVector, long timestamp) {
this.value = value;
this.versionVector = versionVector;
this.timestamp = timestamp;
}读取值时,客户端可以时间戳获取最新的值。在这种情况下,版本向量就完全忽略了。
class ClusterClient…
public Optional<TimestampedVersionedValue> getWithLWWW(List<TimestampedVersionedValue> values) {
return values.stream().max(Comparator.comparingLong(v -> v.timestamp));
}读取修复
虽然允许任何集群节点接受写请求可以提高可用性,但重要的是,所有的副本最终都要有相同的数据。一种常见的修复副本方法是在客户端读取数据的时候。
冲突解决后,还可以检测出哪些节点有旧版本。最新版本会发送给有旧版本的节点,这是处理来自客户端读取请求的一部分。这就是所谓的读修复。
考虑如下图所示的场景。两个节点,blue 和 green,都拥有键值“name”对应的值。green 节点有最新的版本,其版本向量为[blue: 1, green:1]。从 blue 和 green 两个副本进行值的读取时,二者可以进行比较,找出哪个节点缺少了最新的版本,然后,向这个集群节点发出一个带有最新版本的更新请求。
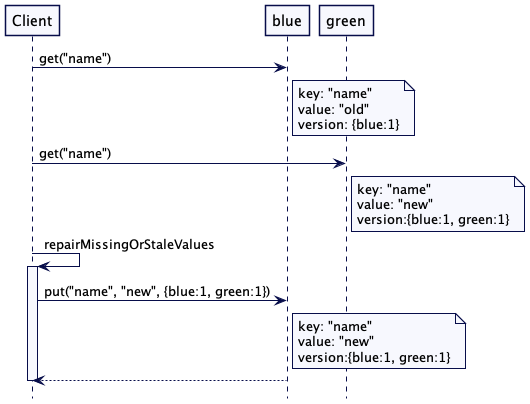
允许同一集群节点并发更新
有这样一种可能性,两个客户端并发写入同一个节点。在上面所示的默认实现中,第二个写入请求会被拒绝。在这种情况下,每个集群节点一个版本号的基本实现是不够的。
考虑下面这种场景。两个客户端尝试更新同样的键值,第二个客户端会得到一个异常,因为在它的更新请求中传递的版本号是过期的。
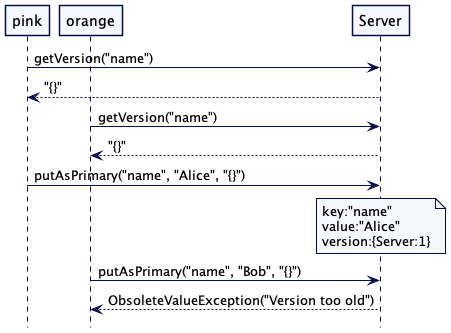
像 riak 这样的数据库会给客户端一些灵活性,允许这样的并发写请求,倾向于不给错误应答。
使用客户端 ID 代替服务端 ID
如果集群的每个客户端都有一个唯一的 ID,就可以使用客户端 ID。每个客户端 ID 对应存储一个版本号。每次客户端写入一个值,它会先读取既有的版本,然后递增同客户端 ID 关联的数字,再写回服务器。
class ClusterClient…
private VersionedValue putWithClientId(String clientId, int nodeIndex, String key, String value, VersionVector version) {
ClusterNode node = clusterNodes.get(nodeIndex);
VersionVector newVersion = version.increment(clientId);
VersionedValue versionedValue = new VersionedValue(value, newVersion);
node.put(key, versionedValue);
return versionedValue;
}因为每个客户端递增的是自己的计数器,并发写会在服务器上创建出自己的兄弟值(sibling value),但并发写却不会失败。
上面提及的场景,第二个客户端出现错误,其运作方式如下:
点状版本向量
基于客户端 ID 的版本向量的一个主要问题是,版本向量的大小直接依赖于客户端的数量。这会导致在一段时间内,集群节点为某个给定的键值积累许多并发值。这个问题成为兄弟爆炸。为了解决这个问题,并依然允许基于集群节点的版本向量,riak 使用了一种版本向量的变体,称为点状版本向量。
样例
voldemort 按照这里描述的方式使用版本向量,其采用的基于时间戳的最后写入胜的冲突解决方案。
riak 开始采用基于客户端 ID 的版本向量,但是,迁移到基于集群节点的版本向量,最终是点状版本向量。Riak 也支持基于系统时间戳的最后写入胜冲突解决方案。
cassandra 并不使用版本向量,它只支持基于系统时间戳的最后写入胜的冲突解决方案。