
复制日志(Replicated Log)
原文
https://martinfowler.com/articles/patterns-of-distributed-systems/replicated-log.html
通过使用复制到所有集群节点的预写日志,保持多个节点的状态同步。
2022.1.11
问题
当多个节点共享一个状态时,该状态就需要同步。所有的集群节点都需要对同样的状态达成一致,即便某些节点崩溃或是断开连接。这需要对每个状态变化请求达成共识。
但仅仅在单个请求上达成共识是不够的。每个副本还需要以相同的顺序执行请求,否则,即使它们对单个请求达成了共识,不同的副本会进入不同的最终状态。
解决方案
集群节点维护了一个预写日志(Write-Ahead Log)。每个日志条目都存储了共识所需的状态以及相应的用户请求。这些节点通过日志条目的协调建立起了共识,这样一来,所有的节点都拥有了完全相同的预写日志。然后,请求按照日志的顺序进行执行。因为所有的集群节点在每条日志条目都达成了一致,它们就是以相同的顺序执行相同的请求。这就确保了所有集群节点共享相同的状态。
使用 Quorum 的容错共识建立机制需要两个阶段。
- 一个阶段负责建立世代时钟(Generation Clock),了解在前一个 Quorum 中复制的日志条目。
- 一个阶段负责在所有集群节点上复制请求。
每次状态变化的请求都去执行两个阶段,这么做并不高效。所以,集群节点会在启动时选择一个领导者。领导者会在选举阶段建立起世代时钟(Generation Clock),然后检测上一个 Quorum 所有的日志条目。(前一个领导者或许已经将大部分日志条目复制到了大多数集群节点上。)一旦有了一个稳定的领导者,复制就只由领导者协调了。客户端与领导者通信。领导者将每个请求添加到日志中,并确保其复制到到所有的追随者上。一旦日志条目成功地复制到大多数追随者,共识就算已经达成。按照这种方式,当有一个稳定的领导者时,对于每次状态变化的操作,只要执行一个阶段就可以达成共识。
多 Paxos 和 Raft
多 Paxos 和 Raft 是最流行的实现复制日志的算法。多 Paxos 只在学术论文中有描述,却又语焉不详。Spanner 和 Cosmos DB 等云数据库采用了多 Paxos,但实现细节却没有很好地记录下来。Raft 非常清楚地记录了所有的实现细节,因此,它成了大多数开源系统的首选实现方式,尽管 Paxos 及其变体在学术界得到了讨论得更多。
复制客户端请求
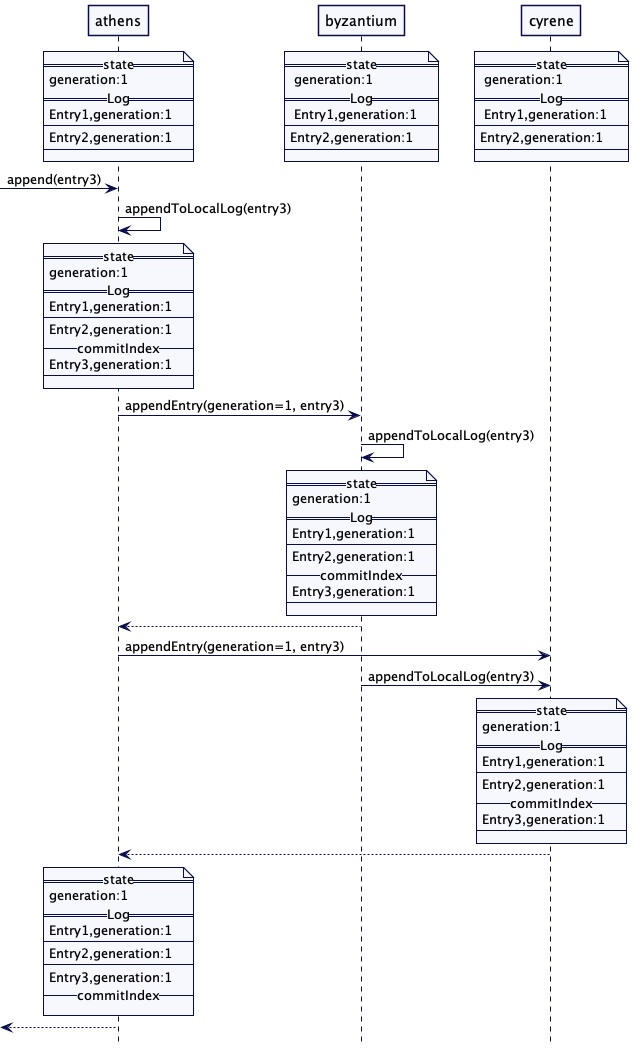
对于每个日志条目而言,领导者会将其追加到其本地的预写日志中,然后,将其发送给所有追随者。
leader (class ReplicatedLog...)
private Long appendAndReplicate(byte[] data) {
Long lastLogEntryIndex = appendToLocalLog(data);
replicateOnFollowers(lastLogEntryIndex);
return lastLogEntryIndex;
}
private void replicateOnFollowers(Long entryAtIndex) {
for (final FollowerHandler follower : followers) {
replicateOn(follower, entryAtIndex); //send replication requests to followers
}
}追随者处理复制请求,将日志条目追加到其本地日志中。在成功追加日志条目后,他们将其拥有的最新日志条目索引回应给领导者。应答还要包括服务器的当前世代时钟。
追随者还会检查日志条目是否已经存在,或者是否存在超出正在复制的日志条目。它会忽略了已经存在的日志条目。但是,如果有来自不同世代的日志条目,它们也会删除存在冲突的日志条目。
follower (class ReplicatedLog...)
void maybeTruncate(ReplicationRequest replicationRequest) {
replicationRequest.getEntries().stream()
.filter(entry -> wal.getLastLogIndex() >= entry.getEntryIndex() &&
entry.getGeneration() != wal.readAt(entry.getEntryIndex()).getGeneration())
.forEach(entry -> wal.truncate(entry.getEntryIndex()));
}
follower (class ReplicatedLog...)
private ReplicationResponse appendEntries(ReplicationRequest replicationRequest) {
List<WALEntry> entries = replicationRequest.getEntries();
entries.stream()
.filter(e -> !wal.exists(e))
.forEach(e -> wal.writeEntry(e));
return new ReplicationResponse(SUCCEEDED, serverId(), replicationState.getGeneration(), wal.getLastLogIndex());
}当复制请求中的世代数低于服务器知道的最新世代数时,跟随者会拒绝这个复制请求。这样一来就给了领导一个通知,让它下台,变成一个追随者。
follower (class ReplicatedLog...)
Long currentGeneration = replicationState.getGeneration();
if (currentGeneration > request.getGeneration()) {
return new ReplicationResponse(FAILED, serverId(), currentGeneration, wal.getLastLogIndex());
}收到响应后,领导者会追踪每个服务器上复制的日志索引。领导者会利用它 追踪成功复制到 Quorum 日志条目,这个索引会当做提交索引(commitIndex)。commitIndex 就是日志中的高水位标记(High-Water Mark)
leader (class ReplicatedLog...)
logger.info("Updating matchIndex for " + response.getServerId() + " to " + response.getReplicatedLogIndex());
updateMatchingLogIndex(response.getServerId(), response.getReplicatedLogIndex());
var logIndexAtQuorum = computeHighwaterMark(logIndexesAtAllServers(), config.numberOfServers());
var currentHighWaterMark = replicationState.getHighWaterMark();
if (logIndexAtQuorum > currentHighWaterMark && logIndexAtQuorum != 0) {
applyLogEntries(currentHighWaterMark, logIndexAtQuorum);
replicationState.setHighWaterMark(logIndexAtQuorum);
}
leader (class ReplicatedLog...)
Long computeHighwaterMark(List<Long> serverLogIndexes, int noOfServers) {
serverLogIndexes.sort(Long::compareTo);
return serverLogIndexes.get(noOfServers / 2);
}
leader (class ReplicatedLog...)
private void updateMatchingLogIndex(int serverId, long replicatedLogIndex) {
FollowerHandler follower = getFollowerHandler(serverId);
follower.updateLastReplicationIndex(replicatedLogIndex);
}
leader (class ReplicatedLog...)
public void updateLastReplicationIndex(long lastReplicatedLogIndex) {
this.matchIndex = lastReplicatedLogIndex;
}完全复制
有一点非常重要,就是要确保所有的节点都能收到来自领导者所有的日志条目,即便是节点断开连接,或是崩溃之后又恢复之后。Raft 有个机制确保所有的集群节点能够收到来自领导者的所有日志条目。
在 Raft 的每个复制请求中,领导者还会发送在复制日志条目前一项的日志索引及其世代。如果前一项的日志条目索引和世代与本地日志中的不匹配,追随者会拒绝该请求。这就向领导者表明,追随者的日志需要同步一些较早的日志条目。
follower (class ReplicatedLog...)
if (!wal.isEmpty() && request.getPrevLogIndex() >= wal.getLogStartIndex() &&
generationAt(request.getPrevLogIndex()) != request.getPrevLogGeneration()) {
return new ReplicationResponse(FAILED, serverId(), replicationState.getGeneration(), wal.getLastLogIndex());
}
follower (class ReplicatedLog...)
private Long generationAt(long prevLogIndex) {
WALEntry walEntry = wal.readAt(prevLogIndex);
return walEntry.getGeneration();
}这样,领导者会递减匹配索引(matchIndex),并尝试发送较低索引的日志条目。它会一直这么做,直到追随者接受复制请求。
leader (class ReplicatedLog...)
//rejected because of conflicting entries, decrement matchIndex
FollowerHandler peer = getFollowerHandler(response.getServerId());
logger.info("decrementing nextIndex for peer " + peer.getId() + " from " + peer.getNextIndex());
peer.decrementNextIndex();
replicateOn(peer, peer.getNextIndex());这个对前一项日志索引和世代的检查允许领导者检测两件事。
- 追随者是否存在日志条目缺失。例如,如果追随者只有一个条目,而领导者要开始复制第三个条目,那么,这个请求就会遭到拒绝,直到领导者复制第二个条目。
- 日志中的前一个是否来自不同的世代,与领导者日志中的对应条目相比,是高还是低。领导者会尝试复制索引较低的日志条目,直到请求得到接受。追随者会截断世代不匹配的日志条目。
按照这种方式,领导者通过使用前一项的索引检测缺失或冲突的日志条目,尝试将自己的日志推送给所有的追随者。这就确保了所有的集群节点最终都能收到来自领导者的所有日志条目,即使它们断开了一段时间的连接。
Raft 没有单独的提交消息,而是将提交索引(commitIndex)作为常规复制请求的一部分进行发送。空的复制请求也可以当做心跳发送。因此,commitIndex 会当做心跳请求的一部分发送给追随者。
日志条目以日志顺序执行
一旦领导者更新了它的 commitIndex,它就会按顺序执行日志条目,从上一个 commitIndex 的值执行到最新的 commitIndex 值。一旦日志条目执行完毕,客户端请求就完成了,应答会返回给客户端。
class ReplicatedLog…
private void applyLogEntries(Long previousCommitIndex, Long commitIndex) {
for (long index = previousCommitIndex + 1; index <= commitIndex; index++) {
WALEntry walEntry = wal.readAt(index);
var responses = stateMachine.applyEntries(Arrays.asList(walEntry));
completeActiveProposals(index, responses);
}
}领导者还会在它发送给追随者的心跳请求中发送 commitIndex。追随者会更新 commitIndex,并以同样的方式应用这些日志条目。
class ReplicatedLog…
private void updateHighWaterMark(ReplicationRequest request) {
if (request.getHighWaterMark() > replicationState.getHighWaterMark()) {
var previousHighWaterMark = replicationState.getHighWaterMark();
replicationState.setHighWaterMark(request.getHighWaterMark());
applyLogEntries(previousHighWaterMark, request.getHighWaterMark());
}
}领导者选举
领导者选举就是检测到日志条目在前一个 Quorum 中完成提交的阶段。每个集群节点都会在三种状态下运行:候选者(candidate)、领导者(leader)和追随者(follower)。在追随者状态下,在启动时,集群节点会期待收到来自既有领导者的心跳(HeartBeat)。如果一个追随者在预先确定的时间段内没有听到领导者任何声音,它就会进入到候选者状态,开启领导者选举。领导者选举算法会建立一个新的世代时钟(Generation Clock)值。Raft 将世代时钟(Generation Clock)称为任期(term)。
领导者选举机制也确保当选的领导者拥有 Quorum 所规定的最新日志条目。这是Raft所做的一个优化,避免了日志条目要从以前的 Quorum 转移新的领导者上。
新领导者选举的启动要通过向每个对等服务器发送消息,请求开始投票。
class ReplicatedLog…
private void startLeaderElection() {
replicationState.setGeneration(replicationState.getGeneration() + 1);
registerSelfVote();
requestVoteFrom(followers);
}一旦服务器在某一世代时钟(Generation Clock)投票中得到投票,服务器总会为同样的世代返回同样的投票。这就确保了在选举成功发生的情况下,如果其它服务器以同样的世代请求投票,它是不会当选的。投票请求的处理过程如下:
class ReplicatedLog…
VoteResponse handleVoteRequest(VoteRequest voteRequest) {
//for higher generation request become follower.
// But we do not know who the leader is yet.
if (voteRequest.getGeneration() > replicationState.getGeneration()) {
becomeFollower(LEADER_NOT_KNOWN, voteRequest.getGeneration());
}
VoteTracker voteTracker = replicationState.getVoteTracker();
if (voteRequest.getGeneration() == replicationState.getGeneration() && !replicationState.hasLeader()) {
if(isUptoDate(voteRequest) && !voteTracker.alreadyVoted()) {
voteTracker.registerVote(voteRequest.getServerId());
return grantVote();
}
if (voteTracker.alreadyVoted()) {
return voteTracker.votedFor == voteRequest.getServerId() ?
grantVote():rejectVote();
}
}
return rejectVote();
}
private boolean isUptoDate(VoteRequest voteRequest) {
boolean result = voteRequest.getLastLogEntryGeneration() > wal.getLastLogEntryGeneration()
|| (voteRequest.getLastLogEntryGeneration() == wal.getLastLogEntryGeneration() &&
voteRequest.getLastLogEntryIndex() >= wal.getLastLogIndex());
return result;
}收到大多数服务器投票的服务器会切换到领导者状态。这里的大多数是按照 Quorum 讨论的方式确定的。一旦当选,领导者会持续地向所有的追随者发送心跳(HeartBeat)。如果追随者在指定的时间间隔内没有收到心跳(HeartBeat),就会触发新的领导者选举。
来自上一世代的日志条目
如上节所述,共识算法的第一阶段会检测既有的值,这些值在算法的前几次运行中已经复制过了。另一个关键点是,这些值就会提议为领导者最新世代的值。第二阶段会决定,只有当这些值提议为当前世代的值时,这些值才会得到提交。Raft 不会更新既有日志条目的世代数。因此,如果领导者拥有来自上一世代的日志条目,而这些条目在一些追随者中是缺失的,它不会仅仅根据大多数的 Quorum 就将这些条目标记为已提交。这是因为有其它服务器可能此时处于不可用的状态,但其拥有同样索引但更高世代的条目。如果领导者在没有复制其当前世代这些日志条目的情况下宕机了,这些条目就会被新的领导者改写。所以,在 Raft 中,新的领导者必须在其任期(term)内提交至少一个条目。然后,它可以安全地提交所有以前的条目。大多数实际的 Raft 实现都在领导者选举后,立即提交一个空操作(no-op)的日志项,这个动作会在领导者得到承认为客户端请求提供服务之前。详情请参考 raft-phd 3.6.1节。
一次领导者选举的示例
考虑有五个服务器:雅典(athens)、拜占庭(byzantium)、锡兰(cyrene)、德尔菲(delphi)和以弗所(ephesus)。以弗所是第一代的领导者。它已经把日志条目复制了其自身、德尔菲和雅典。
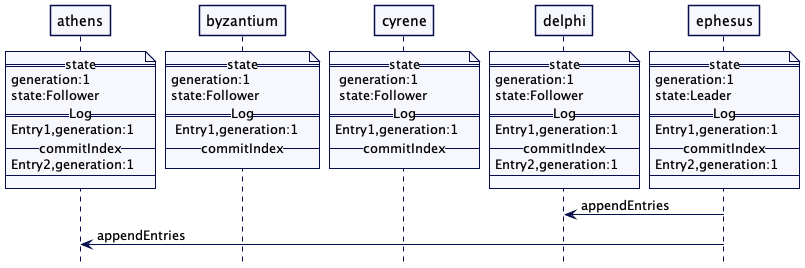
此时,以弗所(ephesus)和德尔菲(delphi)同集群的其它节点失去连接。
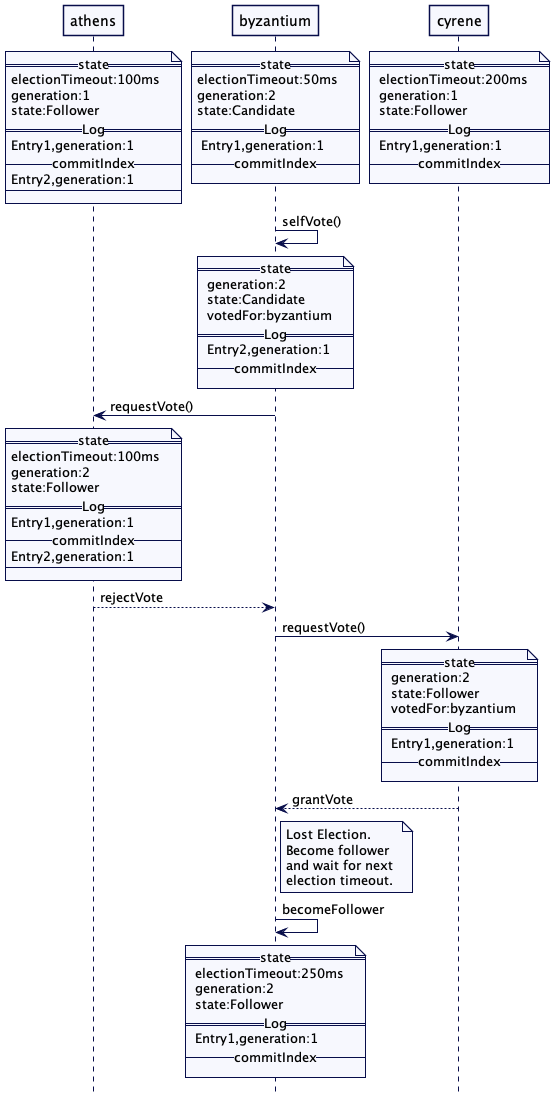
拜占庭(byzantium)有最小的选举超时,因此,它会把世代时钟(Generation Clock)递增到 2,由此触发选举。锡兰(cyrene)其世代小于 2,而且它也有同拜占庭(byzantium)同样的日志条目。因此,它会批准这次投票。但是,雅典(athens)其日志中有额外的条目。因此,它会拒绝这次投票。
因为拜占庭(byzantium)无法获得多数的 3 票,所以,它就失去了选举权,回到追随者状态。
雅典(athens)超时,触发下一轮选举。它将世代时钟(Generation Clock)递增到 3,并向拜占庭(byzantium)和锡兰(cyrene)发送了投票请求。因为拜占庭(byzantium)和锡兰(cyrene)的世代数比较低,也比雅典(athens)的日志条目少,二者都批准了雅典(athens)的投票。一旦雅典(athens)获得了大多数的投票,它就会变成领导者,开始向拜占庭(byzantium)和锡兰(cyrene)发送心跳。一旦拜占庭(byzantium)和锡兰(cyrene)接收到了来自更高世代的心跳,它们会递增他们的世代。这就确认了雅典(athens)的领导者地位,雅典(athens)随后就会将自己的日志复制给拜占庭(byzantium)和锡兰(cyrene)。
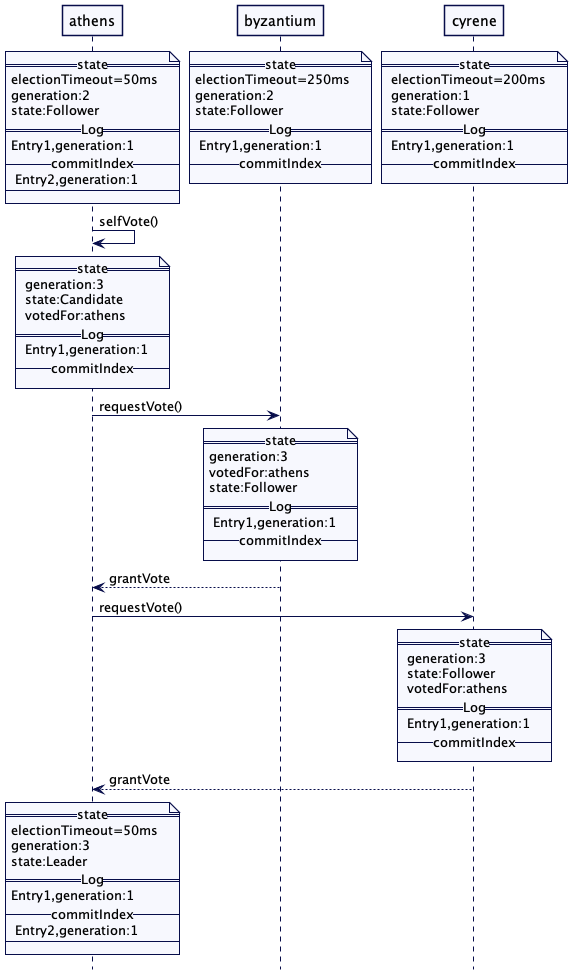
雅典(athens)现在将来自世代 1 的 Entry2 复制给拜占庭(byzantium)和锡兰(cyrene)。但由于它是上一代的日志条目,即便 Entry2 成功的在大多数 Quorum 上复制,它也不会更新提交索引(commitIndex)。
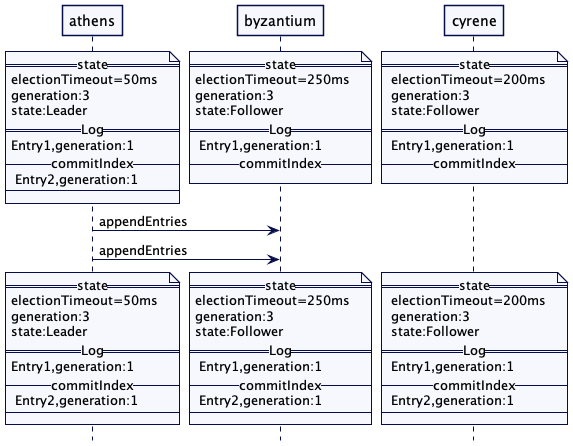
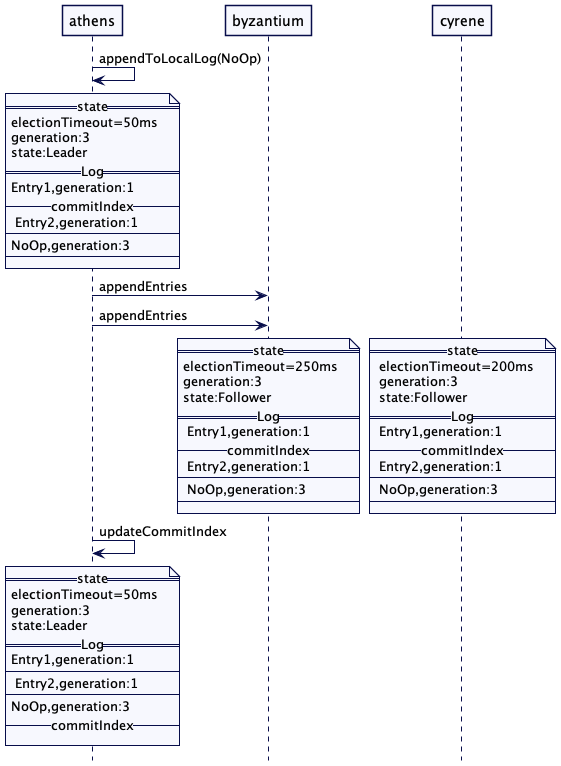
雅典(athens)在其本地日志中追加了一个空操作(no-op)的条目。在这个第 3 代的新条目成功复制后,它会更新提交索引(commitIndex)。
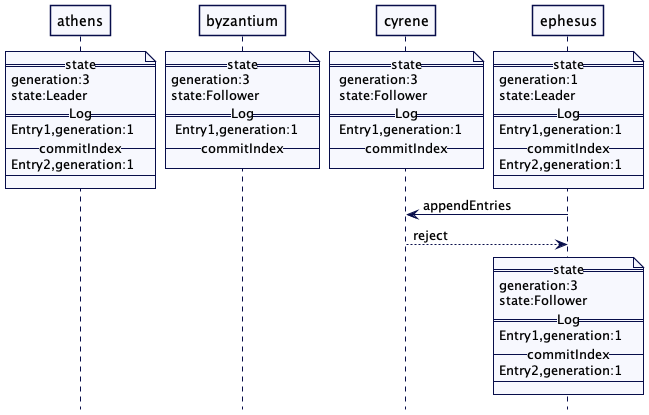
如果以弗所(ephesus)回来或是恢复了网络连接,它会向锡兰(cyrene)发送请求。因为锡兰(cyrene)现在是第 3 代了,它会拒绝这个请求。以弗所(ephesus)会在拒绝应答中得到新的任期(term),下台成为一个追随者。
技术考量
以下是任何复制日志机制都需要有的一些重要技术考量。
- 任何共识建立机制的第一阶段都需要了解日志条目在上一个 Quorum 上可能已经复制过了。领导者需要了解所有这些条目,确保它们复制到集群的每个节点上。
Raft 会确保当选领导者的集群节点拥有同服务器的 Quorum 拥有同样的最新日志,所以,日志条目无需从其它集群节点传给新的领导者。
有可能一些条目存在冲突。在这种情况下,追随者日志中冲突的条目会被覆盖。
- 有可能集群中的一些集群节点落后了,可能是因为它们崩溃后重新启动,可能是与领导者断开了连接。领导者需要跟踪每个集群节点,确保它发送了所有缺失的日志条目。
Raft 会为每个集群节点维护一个状态,以便了解在每个节点上都已成功复制的日志条目的索引。向每个节点发送的复制请求都会包含从这个日志索引开始的所有条目,确保每个集群节点获得所有的日志条目。
- 客户端如何与复制日志进行交互,以找到领导,这个实现在一致性内核(Consistent Core)中讨论过。
在客户端重试的情况下,集群会检测重复的请求,通过采用幂等接收者(Idempotent Receiver)就可以进行处理。
日志通常会用低水位标记(Low-Water Mark)进行压缩。复制日志会周期性地进行存储快照,比如,几千个条目之后就快照一次。然后,快照索引之前的日志就可以丢弃了。缓慢的追随者,或是新加入的服务器,需要发送完整的日志,发给它们的就是快照,而非单独的日志条目。
这里的一个关键假设,所有的请求都是严格有序的。这可能并非总能满足的需求。例如,一个键值存储可能不需要对不同键值的请求进行排序。在这种情况下,有可能为每个键值运行一个不同的共识实例。这样一来,就不需要对所有的请求都有单一的领导者了。
EPaxos 就是一种不依赖单一领导者对请求进行排序的算法。
在像 MongoDB 这样的分区数据库中,每个分区都会维护一个复制日志。因此,请求是按分区排序的,而非跨分区。
推送(Push) vs. 拉取(Pull)
在这里解释的 Raft 复制机制中,领导者可以将所有日志条目推送给追随者,也可以让追随者来拉取日志条目。Kafka 的 Raft 实现就遵循了基于拉取的复制。
日志里有什么?
复制日志机制广泛地用于各种应用之中,从键值存储到区块链。
对键值存储而言,日志条目是关于设置键值与值的。对于租约(Lease)而言,日志条目是关于设置命名租约的。对于区块链而言,日志条目是区块链中的区块,它需要以同样的顺序提供给所有的对等体(peer)。对于像 MongoDB 这样的数据库而言,日志条目就是需要持续复制的数据。
示例
复制日志是 Raft、多 Paxos、Zab 和 viewstamped 复制协议使用的机制。这种技术被称为状态机复制,各个副本都以以相同的顺序执行相同的命令。一致性内核(Consistent Core)通常是用状态机复制机制构建出来的。
像 hyperledger fabric这样的区块链实现有一个排序组件,它是基于复制日志的机制。之前版本的 hyperledger fabric 使用 Kafka对区块链中的区块进行排序。最近的版本则使用 Raft 达成同样的目的。