
请求管道(Request Pipeline)
原文
https://martinfowler.com/articles/patterns-of-distributed-systems/request-pipeline.html
在连接上发送多个请求,而无需等待之前请求的应答,以此改善延迟。
2020.8.20
问题
在集群里服务器间使用单一 Socket 通道(Single Socket Channel)进行通信,如果一个请求需要等到之前请求对应应答的返回,这种做法可能会导致性能问题。为了达到更好的吞吐和延迟,服务端的请求队列应该充分填满,确保服务器容量得到完全地利用。比如,当服务器端使用了单一更新队列(Singular Update Queue),只要队列未填满,就可以继续接收更多的请求。如果只是一次只发一个请求,大多数服务器容量就毫无必要地浪费了。
解决方案
节点向另外的节点发送请求,无需等待之前请求的应答。只要创建两个单独的线程就可以做到,一个在网络通道上发送请求,一个从网络通道上接受应答。
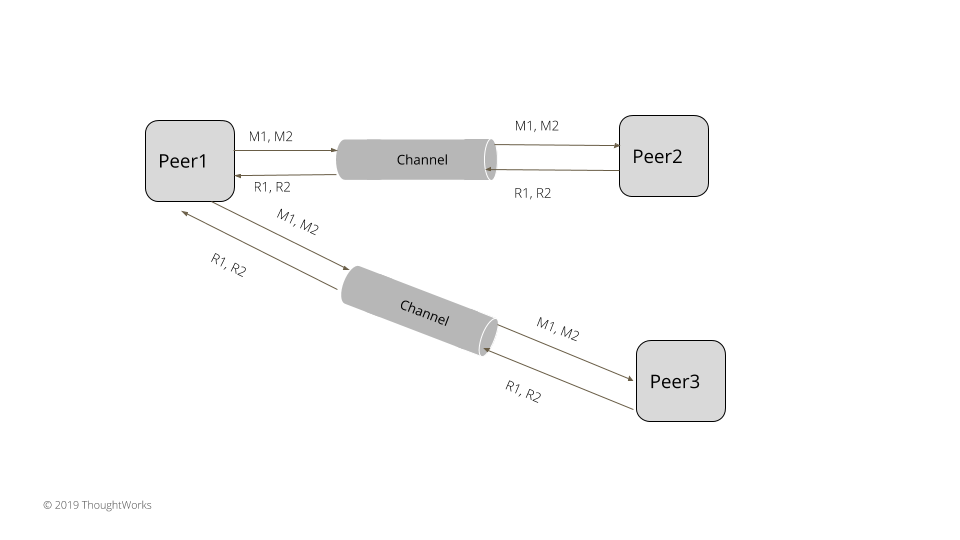
发送者节点通过 socket 通道发送请求,无需等待应答。
class SingleSocketChannel…
public void sendOneWay(RequestOrResponse request) throws IOException {
var dataStream = new DataOutputStream(socketOutputStream);
byte[] messageBytes = serialize(request);
dataStream.writeInt(messageBytes.length);
dataStream.write(messageBytes);
}启动一个单独的线程用以读取应答。
class ResponseThread…
class ResponseThread extends Thread implements Logging {
private volatile boolean isRunning = false;
private SingleSocketChannel socketChannel;
public ResponseThread(SingleSocketChannel socketChannel) {
this.socketChannel = socketChannel;
}
@Override
public void run() {
try {
isRunning = true;
logger.info("Starting responder thread = " + isRunning);
while (isRunning) {
doWork();
}
} catch (IOException e) {
e.printStackTrace();
getLogger().error(e); //thread exits if stopped or there is IO error
}
}
public void doWork() throws IOException {
RequestOrResponse response = socketChannel.read();
logger.info("Read Response = " + response);
processResponse(response);
}应答处理器可以理解处理应答,或是将它提交到单一更新队列里(Singular Update Queue)。
请求管道有两个问题需要处理。
如果无需等待应答,请求持续发送,接收请求的节点就可能会不堪重负。有鉴于此,一般会有一个上限,也就是一次可以有多少在途请求。任何一个节点都可以发送最大数量的请求给其它节点。一旦发出且未收到应答的请求数量达到最大值,再发送请求就不能再接收了,发送者就要阻塞住了。限制最大在途请求,一个非常简单的策略就是,用一个阻塞队列来跟踪请求。队列可以用可接受的最大在途请求数量进行初始化。一旦接收到一个请求的应答,就从队列中把它移除,为更多的请求创造空间。在下面的代码中,每个 socket 连接接收的最大请求数量是 5 个。
class RequestLimitingPipelinedConnection…
private final Map<InetAddressAndPort, ArrayBlockingQueue<RequestOrResponse>> inflightRequests = new ConcurrentHashMap<>();
private int maxInflightRequests = 5;
public void send(InetAddressAndPort to, RequestOrResponse request) throws InterruptedException {
ArrayBlockingQueue<RequestOrResponse> requestsForAddress = inflightRequests.get(to);
if (requestsForAddress == null) {
requestsForAddress = new ArrayBlockingQueue<>(maxInflightRequests);
inflightRequests.put(to, requestsForAddress);
}
requestsForAddress.put(request);一旦接收到应答,请求就从在途请求中移除。
class RequestLimitingPipelinedConnection…
private void consume(SocketRequestOrResponse response) {
Integer correlationId = response.getRequest().getCorrelationId();
Queue<RequestOrResponse> requestsForAddress = inflightRequests.get(response.getAddress());
RequestOrResponse first = requestsForAddress.peek();
if (correlationId != first.getCorrelationId()) {
throw new RuntimeException("First response should be for the first request");
}
requestsForAddress.remove(first);
responseConsumer.accept(response.getRequest());
}处理失败,以及要维护顺序的保证,这些都会让实现变得比较诡异。比如,有两个在途请求。第一个请求失败,然后,重试了,服务器在重试的第一个请求到达服务器之前,已经把第二个请求处理了。服务器需要有一些机制,确保拒绝掉乱序的请求。否则,如果有失败和重试的情况,就会存在消息重排序的风险。比如,Raft 总是发送之前的日志索引,我们会预期,每个日志条目都会有这么个索引。如果之前的日志索引无法匹配,服务器就会拒绝掉这个请求。Kafka 允许 max.in.flight.requests.per.connection 大于 1,还有幂等的 Producer 实现,它会给发送到 Broker 的每个消息批次分配一个唯一标识符。Broker 可以检查进来的请求序列号,如果这边的请求已经乱序,则拒绝掉新请求。
示例
Kafka鼓励客户端使用请求通道来改善吞吐。