
心跳(HeartBeat)
原文
https://martinfowler.com/articles/patterns-of-distributed-systems/heartbeat.html
通过周期性地发送消息给所有其它服务器,表明一个服务器处于可用状态。
2020.8.20
问题
如果集群里有多个服务器,根据所用的分区和复制的模式,各个服务器都要负责存储一部分数据。及时检测出服务器的失败是很重要的,这样可以确保采用一些修正的行动,让其它服务器负责处理失败服务器对应数据的请求。
解决方案
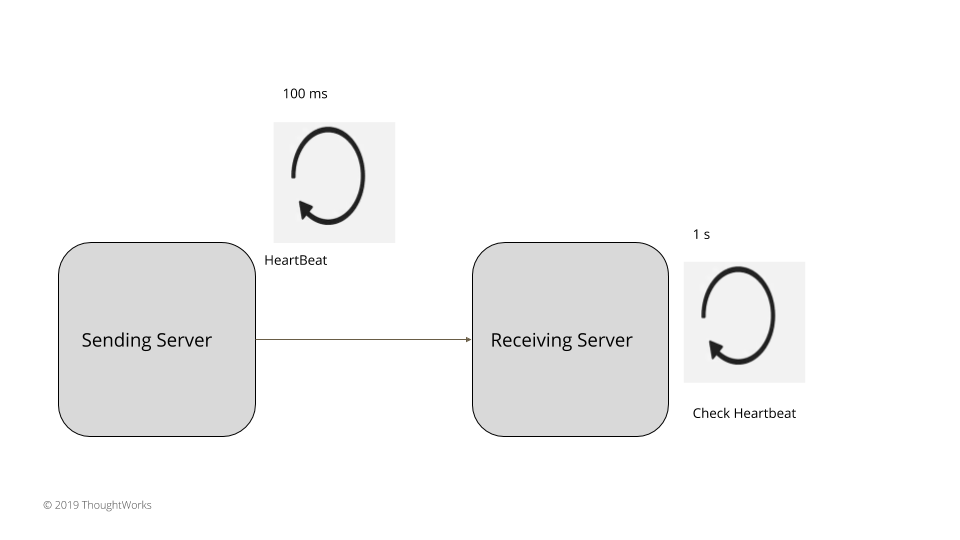
一个服务器周期性地发送请求给所有其它的服务器,以此表明它依然活跃。选择的请求间隔应该大于服务器间的网络往返的时间。所有的服务器在检查心跳时,都要等待一个超时间隔,超时间隔应该是多个请求间隔。通常来说,
超时间隔 > 请求间隔 > 服务器间的网络往返时间
比如,如果服务器间的网络往返时间是 20ms,心跳可以每 100ms 发送一次,服务器检查在 1s 之后执行,这样就给了多个心跳足够的时间,不会产生漏报。如果在这个间隔里没收到心跳,就可以说发送服务器已经失效了。
无论是发送心跳的服务器,还是接收心跳的服务器,都有一个调度器,定义如下。调度器会接受一个方法,以固定的间隔执行。启动时,任务就会开始调度,执行给定的方法。
class HeartBeatScheduler…
public class HeartBeatScheduler implements Logging {
private ScheduledThreadPoolExecutor executor = new ScheduledThreadPoolExecutor(1);
private Runnable action;
private Long heartBeatInterval;
public HeartBeatScheduler(Runnable action, Long heartBeatIntervalMs) {
this.action = action;
this.heartBeatInterval = heartBeatIntervalMs;
}
private ScheduledFuture<?> scheduledTask;
public void start() {
scheduledTask = executor.scheduleWithFixedDelay(new HeartBeatTask(action), heartBeatInterval, heartBeatInterval, TimeUnit.MILLISECONDS);
}在发送端的服务器,调度器会执行方法,发送心跳消息。
class SendingServer…
private void sendHeartbeat() throws IOException {
socketChannel.blockingSend(newHeartbeatRequest(serverId));
}在接收端的服务器,失效检测机制要启动一个类似的调度器。在固定的时间间隔,检查心跳是否收到。
class AbstractFailureDetector…
private HeartBeatScheduler heartbeatScheduler = new HeartBeatScheduler(this::heartBeatCheck, 100l);
abstract void heartBeatCheck();
abstract void heartBeatReceived(T serverId);失效检测器需要有两个方法:
- 接收服务器接收到心跳调用的方法,告诉失效检测器,心跳收到了。
class ReceivingServer…
private void handleRequest(Message<RequestOrResponse> request) {
RequestOrResponse clientRequest = request.getRequest();
if (isHeartbeatRequest(clientRequest)) {
HeartbeatRequest heartbeatRequest = JsonSerDes.deserialize(clientRequest.getMessageBodyJson(), HeartbeatRequest.class);
failureDetector.heartBeatReceived(heartbeatRequest.getServerId());
sendResponse(request);
} else {
//processes other requests
}
}- 一个周期性调用的方法,检查心跳状态,检测可能的失效。
什么时候将服务器标记为失效,这个实现取决于不同的评判标准。其中是有一些权衡的。总的来说,心跳间隔越小,失效检测得越快,但是,也就更有可能出现失效检测的误报。因此,心跳间隔和心跳丢失的解释是按照集群的需求来的。总的来说,分成下面两大类。
小集群,比如,像Raft、Zookeeper等基于共识的系统
在所有的共识实现中,心跳是从领导者服务器发给所有追随者服务器的。每次收到心跳,都要记录心跳到达的时间戳。
class TimeoutBasedFailureDetector…
@Override
void heartBeatReceived(T serverId) {
Long currentTime = System.nanoTime();
heartbeatReceivedTimes.put(serverId, currentTime);
markUp(serverId);
}如果固定的时间窗口内没有收到心跳,就可以认为领导者崩溃了,需要选出一个新的服务器成为领导者。由于进程或网络缓慢,可能会一些虚报的失效。因此,世代时钟(Generation Clock)常用来检测过期的领导者。这就给系统提供了更好的可用性,这样很短的时间周期里就能检测出崩溃。对于比较小的集群,这很适用,典型的就是有三五个节点,大多数共识实现比如 Zookeeper 或 Raft 都是这样的。
class TimeoutBasedFailureDetector…
@Override
void heartBeatCheck() {
Long now = System.nanoTime();
Set<T> serverIds = heartbeatReceivedTimes.keySet();
for (T serverId : serverIds) {
Long lastHeartbeatReceivedTime = heartbeatReceivedTimes.get(serverId);
Long timeSinceLastHeartbeat = now - lastHeartbeatReceivedTime;
if (timeSinceLastHeartbeat >= timeoutNanos) {
markDown(serverId);
}
}
}技术考量
采用单一 Socket 通道(Single Socket Channel)在服务器间通信时,有一点需要考虑,就是队首阻塞(head-of-line-blocking),这会让心跳消息得不到处理。这样一来,延迟就会非常长,以致于产生虚报,认为发送服务器已经宕机,即便它还在按照固定的间隔发送心跳。使用请求管道(Request Pipeline),可以保证服务器在发送心跳之前不必等待之前请求的应答回来。有时,使用单一更新队列(Singular Update Queue),像写磁盘这样的任务,就可能会造成延迟,这可能会延迟定时中断的处理,也会延迟发送心跳。
这个问题可以通过在单独的线程中异步发送心跳来解决。类似于 consul 和 akka 这样的框架都会异步发送心跳。对于接收者服务器同样也是一个问题。接收服务器也要进行磁盘写,检查心跳只能在写完成后才能检查心跳,这就会造成虚报的失效检测。因此接收服务器可以使用单一更新队列(Singular Update Queue),解决心跳检查机制的延迟问题。raft 的参考实现、log-cabin 就是这么做的。
有时,一些运行时特定事件,比如垃圾收集,会造成本地停顿,进而造成心跳处理的延迟。这就需要有一种机制在本地暂停(可能)发生后,检查心跳处理是否发生过。一个简单的机制就是,在一段足够长的时间窗口之后(如,5s),检查是否有心跳。在这种情况下,如果在这个时间窗口内不需要标记为心跳失效,那么就进入到下一个循环。Cassandra 的实现就是这种做法的一个很好的示例。
大集群,基于 Gossip 的协议
前面部分描述的心跳机制,并不能扩展到大规模集群,也就是那种有几百到上千台服务器,横跨广域网的集群。在大规模集群中,有两件事要考虑:
- 每台服务器生成的消息数量要有一个固定的限制。
- 心跳消息消耗的总共的带宽。它不该消耗大量的网络带宽。应该有个几百 K 字节的上限,确保即便有太多的心跳也不会影响到在集群上实际传输的数据。
基于这些原因,应该避免所有节点对所有节点的心跳。在这些情况下,通常会使用失效检测器,以及 Gossip 协议,在集群中传播失效信息。在失效的场景下,这些集群会采取一些行动,比如,在节点间搬运数据,因此,集群会倾向于进行正确性的检测,容忍更多的延迟(虽然是有界的)。这里的主要挑战在于,不要因为网络的延迟或进程的缓慢,造成对于节点失效的虚报。那么,一种常用的机制是,给每个进程分配一个怀疑计数,在限定的时间内,如果没有收到该进程的 Gossip 消息,则怀疑计数递增。它可以根据过去的统计信息计算出来,只有在这个怀疑计数到达配置的上限时,才将其标记为失效。
有两种主流的实现:1)Phi Accrual 的失效检测器(用于 Akka、Cassandra),2)带 Lifeguard 增强的SWIM(用于 Hashicop Consul、memberlist)。这种实现可以在有数千台机器的广域网上扩展。据说 Akka 尝试过 2400 台服务器。Hashicorp Consul 在一个群组内常规部署了几千台 consul 服务器。有一个可靠的失效检测器,可以有效地用于大规模集群部署,同时,又能提供一些一致性保证,这仍然是一个积极发展中的领域。最近在一些框架的研究看上去非常有希望,比如 Rapid。
示例
- 共识实现,诸如 ZAB 或 RAFT,可以在三五个节点的集群中很好的运行,实现了基于固定时间窗口的失效检测。
- Akka Actor 和 Cassandra 采用 Phi Accrual 的失效检测器。
- Hashicorp consul 采用了基于 Gossip 的失效检测器 SWIM。