
领导者和追随者(Leader and Followers)
原文
https://martinfowler.com/articles/patterns-of-distributed-systems/leader-follower.html
有一台服务器协调一组服务器间的复制。
2020.8.6
问题
对于一个管理数据的系统而言,为了在系统内实现容错,需要将数据复制到多台服务器上。
有一点也很重要,就是给客户提供一些一致性的保证。当数据在多个服务器上更新时,需要决定何时让客户端看到这些数据。只有写读的 Quorum 是不够的,因为一些失效的场景会导致客户端看到不一致的数据。单个的服务器并不知道 Quorum 上其它服务器的数据状态,只有数据是从多台服务器上读取时,才能解决不一致的问题。在某些情况下,这还不够。发送给客户端的数据需要有更强的保证。
解决方案
在集群里选出一台服务器成为领导者。领导者负责根据整个集群的行为作出决策,并将决策传给其它所有的服务器。
每台服务器在启动时都会寻找一个既有的领导者。如果没有找到,它会触发领导者选举。只有在领导者选举成功之后,服务器才会接受请求。只有领导者才会处理客户端的请求。如果一个请求发送到一个追随者服务器,追随者会将其转发给领导者服务器。
领导者选举
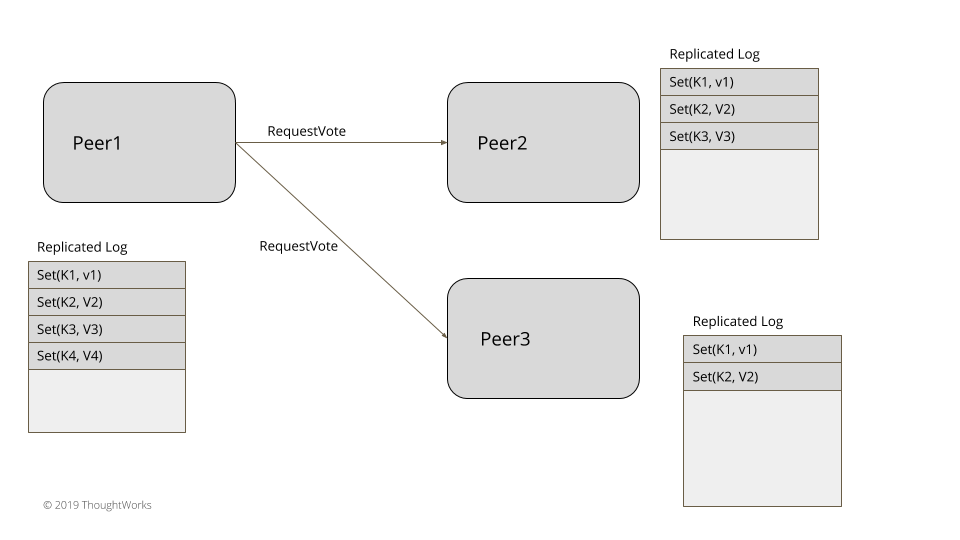
对于三五个节点的小集群,比如在实现共识的系统中,领导者选举可以在数据集群内部实现,不依赖于任何外部系统。领袖选举发生在服务器启动时。每台服务器在启动时都会启动领导者选举,尝试选出一个领导者。在选出一个领导者之前,系统不会接收客户端的任何请求。正如在世代时钟(Generation Clock)模式中所阐释的那样,每次领导者选举都需要更新世代号。服务器总是处于三种状态之一:领导者、追随者或是寻找领导者(或候选者)。
public enum ServerRole {
LOOKING_FOR_LEADER,
FOLLOWING,
LEADING;
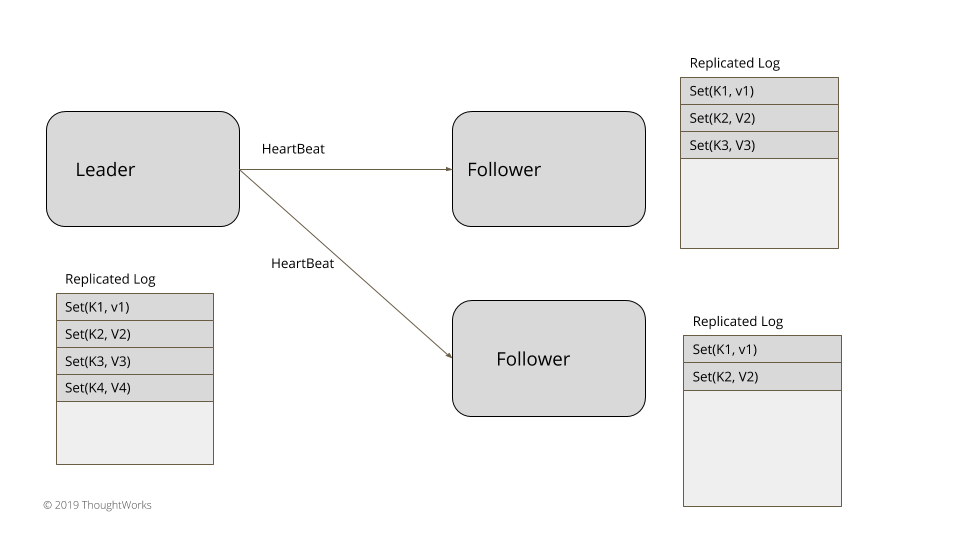
}心跳(HeartBeat)机制用以检测既有的领导者是否失效,以便启动新的领导者选举。
通过给其它对等的服务器发送消息,启动投票,一次新的选举就开始了。
class ReplicationModule…
private void startLeaderElection() {
replicationState.setGeneration(replicationState.getGeneration() + 1);
registerSelfVote();
requestVoteFrom(followers);
}选举算法
选举领导者时,有两个因素要考虑:
- 因为这个系统主要用于数据复制,哪台服务器可以赢得选举就要做出一些额外的限制。只有“最新”的服务器才能成为合法的领导者。比如说,在典型的基于共识的系统中,“最新”由两件事定义:
- 如果所有的服务器都是最新的,领导者可以根据下面的标准来选:
- 一些实现特定的标准,比如,哪个服务器评级为更好或有更高的 ID(比如,Zab)
- 如果要保证注意每台服务器一次只投一票,就看哪台服务器先于其它服务器启动选举。(比如,Raft)
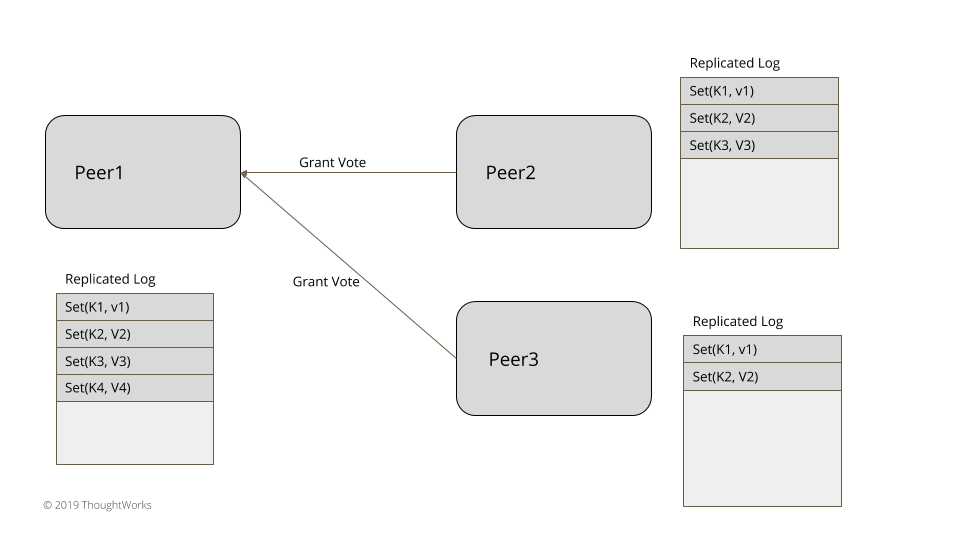
在给定的世代时钟(Generation Clock)内,一旦某台服务器得到投票,在同一个时代内,投票就总是一样的。这就确保了在成功的选举之后,其它服务器再发起同样世代的投票也不会当选。投票请求的处理过程如下:
class ReplicationModule…
VoteResponse handleVoteRequest(VoteRequest voteRequest) {
VoteTracker voteTracker = replicationState.getVoteTracker();
Long requestGeneration = voteRequest.getGeneration();
if (replicationState.getGeneration() > requestGeneration) {
return rejectVote();
} else if (replicationState.getGeneration() < requestGeneration) {
becomeFollower(-1, requestGeneration);
voteTracker.registerVote(voteRequest.getServerId());
return grantVote();
}
return handleVoteRequestForSameGeneration(voteRequest);
}
private VoteResponse handleVoteRequestForSameGeneration(VoteRequest voteRequest) {
Long requestGeneration = voteRequest.getGeneration();
VoteTracker voteTracker = replicationState.getVoteTracker();
if (voteTracker.alreadyVoted()) {
return voteTracker.grantedVoteForSameServer(voteRequest.getServerId()) ?
grantVote():rejectVote();
}
if (voteRequest.getLogIndex() >= (Long) wal.getLastLogEntryId()) {
becomeFollower(NO_LEADER_ID, requestGeneration);
voteTracker.registerVote(voteRequest.getServerId());
return grantVote();
}
return rejectVote();
}
private void becomeFollower(int leaderId, Long generation) {
replicationState.setGeneration(generation);
replicationState.setLeaderId(leaderId);
transitionTo(ServerRole.FOLLOWING);
}
private VoteResponse grantVote() {
return VoteResponse.granted(serverId(),
replicationState.getGeneration(),
wal.getLastLogEntryId());
}
private VoteResponse rejectVote() {
return VoteResponse.rejected(serverId(),
replicationState.getGeneration(),
wal.getLastLogEntryId());
}获得多数服务器投票的服务器将转成领导者状态。大多数的确定是根据 Quorum 中所讨论的那样。一旦当选,领导者会持续给所有的追随者发送心跳(HeartBeat)。如果追随者在特定的时间间隔内没有收到心跳,就会触发新的领导选举。
使用外部[线性化]的存储进行领导者选举
在一个数据集群内运行领导者选举,对小集群来说,效果很好。但对那些有数千个节点的大数据集群来说,使用外部存储会更容易一些,比如 Zookeeper 或 etcd (其内部使用了共识,提供了线性化保证)。这些大规模的集群通常都有一个服务器,标记为主节点或控制器节点,代表整个集群做出所有的决策。实现领导者选举要有三个功能:
- compareAndSwap 指令,能够原子化地设置一个键值。
- 心跳的实现,如果没有从选举节点收到心跳,将键值做过期处理,以便触发新的选举。
- 通知机制,如果一个键值过期,就通知所有感兴趣的服务器。
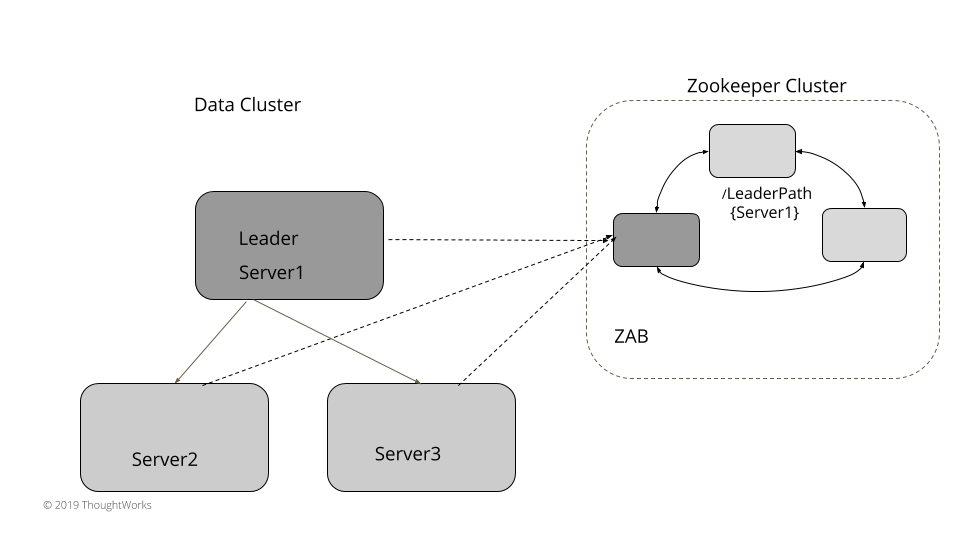
在选举领导者时,每个服务器都会使用 compareAndSwap 指令尝试在外部存储中创建一个键值,哪个服务器先成功,就当选为领导者。根据所用的外部存储,键值创建后有一小段的存活时间。当选的领导在存活时间之前都会反复更新键值。每台服务器都会监控这个键值,如果键值已经过期,而且没有在设置的存活时间内收到来自既有领导者的更新,服务器会得到通知。比如,etcd 允许 compareAndSwap 操作这样做,只在键值之前不存在时设置键值。在 Zookeeper 里,没有支持显式的 compareAndSwap 这种操作,但可以这样来实现,尝试创建一个节点,如果这个节点已经存在,就抛出一个异常。Zookeeper 也没有存活时间,但它有个临时节点(ephemeral node)的概念。只要服务器同 Zookeeper 间有一个活跃的会话,这个节点就会存在,否则,节点就会删除,每个监控这个节点的人都会得到通知。比如,用 Zookeeper 可以像下面这样选举领导者:
class ServerImpl…
public void startup() {
zookeeperClient.subscribeLeaderChangeListener(this);
elect();
}
public void elect() {
var leaderId = serverId;
try {
zookeeperClient.tryCreatingLeaderPath(leaderId);
this.currentLeader = serverId;
onBecomingLeader();
} catch (ZkNodeExistsException e) {
//back off
this.currentLeader = zookeeperClient.getLeaderId();
}
}所有其它的服务器都会监控既有领导者的活跃情况。当它检测到既有领导者宕机时,就会触发新的领导者选举。失效检测要使用与领导者选举相同的外部线性化存储。这个外部存储要有一些设施,实现分组成员信息以及失效检测机制。比如,扩展上面基于 Zookeeper 的实现,在 Zookeeper 上配置一个变化监听器,在既有领导者发生改变时,该监听器就会触发。
class ZookeeperClient…
public void subscribeLeaderChangeListener(IZkDataListener listener) {
zkClient.subscribeDataChanges(LeaderPath, listener);
}集群中的每个服务器都会订阅这个变化,当回调触发之后,就会触发一次新选举,方式如上所示。
class ServerImpl…
@Override
public void handleDataDeleted(String dataPath) throws Exception {
elect();
}
用同样的方式使用类似于 etcd 或 Consul 的系统也可以实现领导者选举。
为何 Quorum 读/写不足以保证强一致性
貌似像 Cassandra 这样的 Dynamo 风格的数据库所提供的 Quorum 读/写,足以在服务器失效的情况下获得强一致性。但事实并非如此。考虑一下下面的例子。假设我们有一个三台服务器的集群。变量 x 存在所有三台服务器上(其复制因子是 3)。启动时,x 的值是 1。
- 假设 writer1 写入 x=2,复制因子是 3。写的请求发送给所有的三台服务器。server1 写成功了,然而,server2 和 server3 失败了。(可能是小故障,或者只是 writer1 把请求发送给 server1 之后,陷入了长时间的垃圾收集暂停)。
- 客户端 c1 从 server1 和 server2 读取 x 的值。它得到了x=2 这个最新值,因为 server1 已经有了最新值。
- 客户端 c2 触发去读 x。但是,server1 临时宕机了。因此,c2 要从 server2 和 server 3 去读取,它们拥有的 x 的旧值,x=1。因此,c2 得到的是旧值,即便它们是在 c1 已经得到了最新值之后去读取的。
按照这种方式,连续两次的读取,结果是最新的值消失了。一旦 server1 恢复回来,后续的读还会得到最新的值。假设读取修复或是抗熵进程在运行,服务器“最终”还是会得到最新的值。但是,存储集群无法提供任何保证,确保一旦一个特定的值对任何客户端可见之后,所有后续的读取得到都是那个值,即便服务器失效了。
示例
- 对于实现共识的系统而言,有一点很重要,就是只有一台服务器协调复制过程的行为。正如Paxos Made Simple所指出的,系统的活性很重要。
- 在 Raft 和 Zab 共识算法中,领导者选举是一个显式的阶段,发生在启动时,或是领导者失效时。
- Viewstamp Replication算法有一个 Primary 概念,类似于其它算法中的领导者。
- Kafka 有个 Controller,它负责代表集群的其它部分做出所有的决策。它对来自 Zookeeper 的事件做出响应,Kafka 的每个分区都有一个指定的领导者 Broker 以及追随者 Broker。领导者和追随者选举由 Controller Broker 完成。