
世代时钟(Generation Clock)
原文
https://martinfowler.com/articles/patterns-of-distributed-systems/generation.html
一个单调递增的数字,表示服务器的世代。
2020.8.20
又称:Term、Epoch 或世代(Generation)
问题
在领导者和追随者(Leader and Followers)的构建过程中,有一种可能性,领导者临时同追随者失联了。可能是因为垃圾回收造成而暂停,也可能是临时的网络中断,这些都会让领导者进程与追随者之间失联。在这种情况下,领导者进程依旧在运行,暂停之后或是网络中断停止之后,它还是会尝试发送复制请求给追随者。这么做是有危险的,因为与此同时,集群余下的部分可能已经选出了一个新的领导者,接收来自客户端的请求。有一点非常重要,集群余下的部分要能检测出有的请求是来自原有的领导者。原有的领导者本身也要能检测出,它是临时从集群中断开了,然后,采用必要的修正动作,交出领导权。
解决方案
维护一个单调递增的数字,表示服务器的世代。每次选出新的领导者,这个世代都应该递增。即便服务器重启,这个世代也应该是可用的,因此,它应该存储在预写日志(Write-Ahead Log)每一个条目里。在高水位标记(High-Water Mark)里,我们讨论过,追随者会使用这个信息找出日志中冲突的部分。
启动时,服务器要从日志中读取最后一个已知的世代。
class ReplicationModule…
this.replicationState = new ReplicationState(config, wal.getLastLogEntryGeneration());采用领导者和追随者(Leader and Followers)模式,选举新的领导者选举时,服务器对这个世代的值进行递增。
class ReplicationModule…
private void startLeaderElection() {
replicationState.setGeneration(replicationState.getGeneration() + 1);
registerSelfVote();
requestVoteFrom(followers);
}服务器会把世代当做投票请求的一部分发给其它服务器。在这种方式下,经过了成功的领导者选举之后,所有的服务器都有了相同的世代。一旦选出新的领导者,追随者就会被告知新的世代。
follower (class ReplicationModule...)
private void becomeFollower(int leaderId, Long generation) {
replicationState.setGeneration(generation);
replicationState.setLeaderId(leaderId);
transitionTo(ServerRole.FOLLOWING);
}自此之后,领导者会在它发给追随者的每个请求中都包含这个世代信息。它也包含在发给追随者的每个心跳(HeartBeat)消息里,也包含在复制请求中。
领导者也会把世代信息持久化到预写日志(Write-Ahead Log)的每一个条目里。
leader (class ReplicationModule...)
Long appendToLocalLog(byte[] data) {
var logEntryId = wal.getLastLogEntryId() + 1;
var logEntry = new WALEntry(logEntryId, data, EntryType.DATA, replicationState.getGeneration());
return wal.writeEntry(logEntry);
}按照这种做法,它还会持久化在追随者日志中,作为领导者和追随者(Leader and Followers)复制机制的一部分。
如果追随者得到了一个来自已罢免领导的消息,追随者就可以告知其世代过低。追随者会给出一个失败的应答。
follower (class ReplicationModule...)
Long currentGeneration = replicationState.getGeneration();
if (currentGeneration > replicationRequest.getGeneration()) {
return new ReplicationResponse(FAILED, serverId(), currentGeneration, wal.getLastLogEntryId());
}当领导者得到了一个失败的应答,它就会变成追随者,期待与新的领导者建立通信。
Old leader (class ReplicationModule...)
if (!response.isSucceeded()) {
stepDownIfHigherGenerationResponse(response);
return;
}
private void stepDownIfHigherGenerationResponse(ReplicationResponse replicationResponse) {
if (replicationResponse.getGeneration() > replicationState.getGeneration()) {
becomeFollower(-1, replicationResponse.getGeneration());
}
}考虑一下下面这个例子。在一个服务器集群里,leader1 是既有的领导者。集群里所有服务器的世代都是 1。leader1 持续发送心跳给追随者。leader1 产生了一次长的垃圾收集暂停,比如说,5 秒。追随者没有得到心跳,超时了,然后选举出新的领导者。新的领导者将世代递增到 2。垃圾收集暂停结束之后,leader1 持续发送请求给其它服务器。追随者和新的领导者现在都是世代 2 了,拒绝了其请求,发送一个失败应答,其中的世代是 2。leader1 处理失败的应答,退下来成为一个追随者,将世代更新成 2。
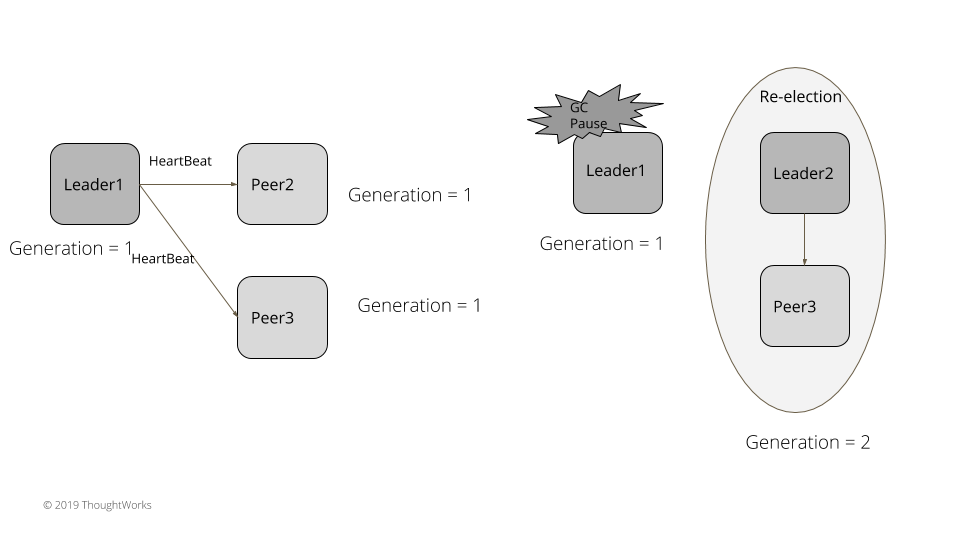
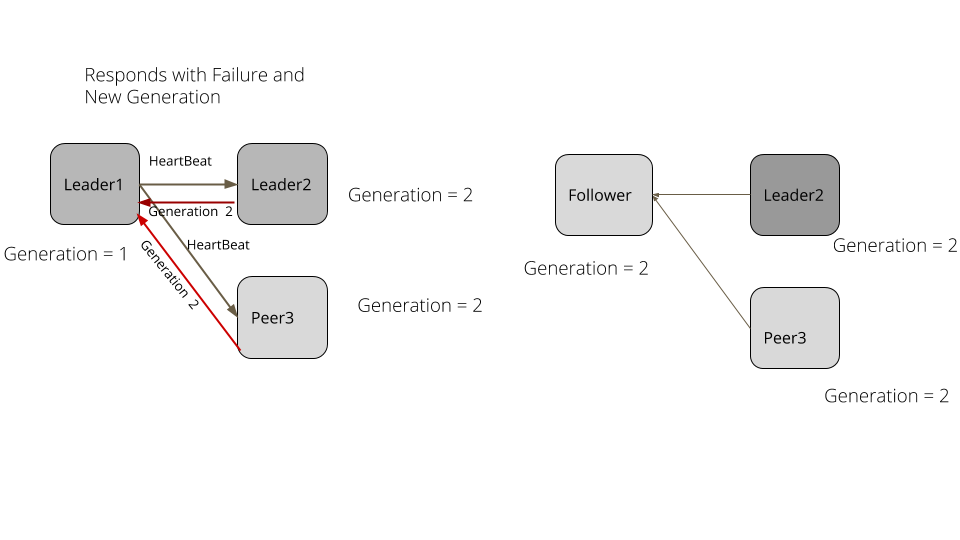
示例
Raft
Raft 使用了 Term 的概念标记领导者世代。
Zab
在 Zookeeper 里,每个 epoch 数是作为每个事务 ID 的一部分进行维护的。因此,每个持久化在 Zookeeper 里的事务都有一个世代,通过 epoch 表示。
Cassandra
在 Cassandra 里,每个服务器都存储了一个世代数字,每次服务器重启时都会递增。世代信息持久化在系统的键值空间里,也作为 Gossip 消息的一部分传给其它服务器。服务器接收到 Gossip 消息之后,将它知道的世代值与 Gossip 消息的世代值进行比较。如果 Gossip 消息中世代更高,它就知道服务器重启了,然后,丢弃它维护的关于这个服务器的所有状态,请求新的状态。
Kafka 中的 Epoch
Kafka 每次为集群选出新的控制器,都会创建一个 epoch 数,将其存在 Zookeeper 里。epoch 会包含在集群里从控制器发到其它服务器的每个请求中。它还维护了另外一个 epoch,称为 LeaderEpoch,以便了解一个分区的追随者是否落后于其高水位标记(High-Water Mark)。