
追随者读取(Follower Reads)
原文
https://martinfowler.com/articles/patterns-of-distributed-systems/follower-reads.html
由追随者为读取请求提供服务,获取更好的吞吐和更低的延迟。
2021.7.1
问题
使用领导者和追随者模式时,如果有太多请求发给领导者,它可能会出现过载。此外,在多数据中心的情况下,客户端如果在远程的数据中心,向领导者发送的请求可能会有额外的延迟。
解决方案
当写请求要到领导者那去维持一致性,只读请求就会转到最近的追随者。当客户端大多都是只读的,这种做法就特别有用。
值得注意的是,从追随者那里读取的客户端得到可能是旧值。领导者和追随者之间总会存在一个复制滞后,即使是在像 Raft 这样实现共识算法的系统中。这是因为即使领导者知道哪些值提交过了,它也需要另外一个消息将这个信息传达给跟随者。因此,从追随者服务器上读取信息只能用于“可以容忍稍旧的值”的情况。
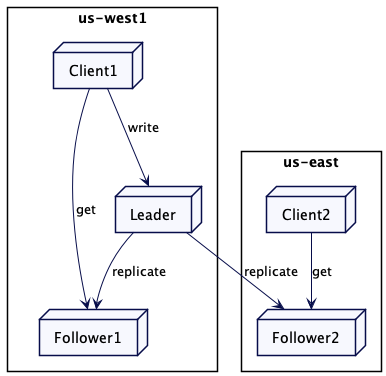
找到最近的节点
集群节点要额外维护其位置的元数据。
class ReplicaDescriptor…
public class ReplicaDescriptor {
public ReplicaDescriptor(InetAddressAndPort address, String region) {
this.address = address;
this.region = region;
}
InetAddressAndPort address;
String region;
public InetAddressAndPort getAddress() {
return address;
}
public String getRegion() {
return region;
}
}然后,集群客户端可以根据自己的区域选取本地的副本。
class ClusterClient…
public List<String> get(String key) {
List<ReplicaDescriptor> allReplicas = allFollowerReplicas(key);
ReplicaDescriptor nearestFollower = findNearestFollowerBasedOnLocality(allReplicas, clientRegion);
GetValueResponse getValueResponse = sendGetRequest(nearestFollower.getAddress(), new GetValueRequest(key));
return getValueResponse.getValue();
}
ReplicaDescriptor findNearestFollowerBasedOnLocality(List<ReplicaDescriptor> followers, String clientRegion) {
List<ReplicaDescriptor> sameRegionFollowers = matchLocality(followers, clientRegion);
List<ReplicaDescriptor> finalList = sameRegionFollowers.isEmpty()?followers:sameRegionFollowers;
return finalList.get(0);
}
private List<ReplicaDescriptor> matchLocality(List<ReplicaDescriptor> followers, String clientRegion) {
return followers.stream().filter(rd -> clientRegion.equals(rd.region)).collect(Collectors.toList());
}例如,如果有两个追随者副本,一个在美国西部(us-west),另一个在美国东部(us-east)。美国东部的客户端就会连接到美国东部的副本上。
class CausalKVStoreTest…
@Test
public void getFollowersInSameRegion() {
List<ReplicaDescriptor> followers = createReplicas("us-west", "us-east");
ReplicaDescriptor nearestFollower = new ClusterClient(followers, "us-east").findNearestFollower(followers);
assertEquals(nearestFollower.getRegion(), "us-east");
}集群客户端或协调的集群节点也会追踪其同集群节点之间可观察的延迟。它可以发送周期性的心跳来获取延迟,并根据它选出延迟最小的追随者。为了做一个更公平的选择,像 mongodb 或 cockroachdb 这样的产品会把延迟当做滑动平均来计算。集群节点一般会同其它集群节点之间维护一个单一 Socket 通道(Single Socket Channel)进行通信。单一 Socket 通道(Single Socket Channel)会使用心跳(HeartBeat)进行连接保活。因此,获取延迟和计算滑动移动平均就可以很容易地实现。
class WeightedAverage…
public class WeightedAverage {
long averageLatencyMs = 0;
public void update(long heartbeatRequestLatency) {
//Example implementation of weighted average as used in Mongodb
//The running, weighted average round trip time for heartbeat messages to the target node.
// Weighted 80% to the old round trip time, and 20% to the new round trip time.
averageLatencyMs = averageLatencyMs == 0
? heartbeatRequestLatency
: (averageLatencyMs * 4 + heartbeatRequestLatency) / 5;
}
public long getAverageLatency() {
return averageLatencyMs;
}
}
class ClusterClient…
private Map<InetAddressAndPort, WeightedAverage> latencyMap = new HashMap<>();
private void sendHeartbeat(InetAddressAndPort clusterNodeAddress) {
try {
long startTimeNanos = System.nanoTime();
sendHeartbeatRequest(clusterNodeAddress);
long endTimeNanos = System.nanoTime();
WeightedAverage heartbeatStats = latencyMap.get(clusterNodeAddress);
if (heartbeatStats == null) {
heartbeatStats = new WeightedAverage();
latencyMap.put(clusterNodeAddress, new WeightedAverage());
}
heartbeatStats.update(endTimeNanos - startTimeNanos);
} catch (NetworkException e) {
logger.error(e);
}
}This latency information can then be used to pick up the follower with the least network latency.
class ClusterClient…
ReplicaDescriptor findNearestFollower(List<ReplicaDescriptor> allFollowers) {
List<ReplicaDescriptor> sameRegionFollowers = matchLocality(allFollowers, clientRegion);
List<ReplicaDescriptor> finalList
= sameRegionFollowers.isEmpty() ? allFollowers
:sameRegionFollowers;
return finalList.stream().sorted((r1, r2) -> {
if (!latenciesAvailableFor(r1, r2)) {
return 0;
}
return Long.compare(latencyMap.get(r1).getAverageLatency(),
latencyMap.get(r2).getAverageLatency());
}).findFirst().get();
}
private boolean latenciesAvailableFor(ReplicaDescriptor r1, ReplicaDescriptor r2) {
return latencyMap.containsKey(r1) && latencyMap.containsKey(r2);
}这样,就可以利用延迟信息选取网络延迟最小的追随者。
class ClusterClient…
ReplicaDescriptor findNearestFollower(List<ReplicaDescriptor> allFollowers) {
List<ReplicaDescriptor> sameRegionFollowers = matchLocality(allFollowers, clientRegion);
List<ReplicaDescriptor> finalList
= sameRegionFollowers.isEmpty() ? allFollowers
:sameRegionFollowers;
return finalList.stream().sorted((r1, r2) -> {
if (!latenciesAvailableFor(r1, r2)) {
return 0;
}
return Long.compare(latencyMap.get(r1).getAverageLatency(),
latencyMap.get(r2).getAverageLatency());
}).findFirst().get();
}
private boolean latenciesAvailableFor(ReplicaDescriptor r1, ReplicaDescriptor r2) {
return latencyMap.containsKey(r1) && latencyMap.containsKey(r2);
}断连或缓慢的追随者
追随者可能会与领导者之间失去联系,停止获得更新。在某些情况下,追随者可能会受到慢速磁盘的影响,阻碍整个的复制过程,这会导致追随者滞后于领导者。追随者追踪到其是否有一段时间没有收到领导者的消息,在这种情况下,可以停止对用户请求进行服务。
比如,像 mongodb 这样的产品会选择带有最大可接受滞后时间(maximum allowed lag time)的副本。如果副本滞后于领导者超过了这个最大时间,就不会选择它继续对用户请求提供服务。在 kafka 中,如果追随者检测到消费者请求的偏移量过大,它就会给出一个 OFFSET_OUT_OF_RANGE 的错误。我们就预期消费者会与领导者进行通信。
读自己写
从追随者服务器读取可能会有问题,当客户端写入一些东西,然后立即尝试读取它时,即便是这样常规的场景,也可能给出令人吃惊的结果。
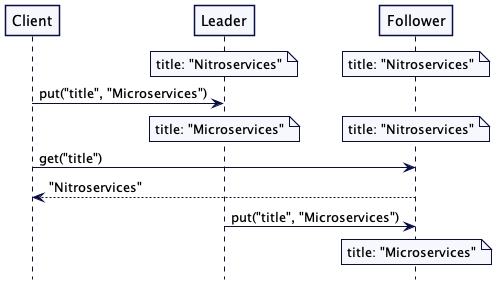
考虑这样一个情况,一个客户端注意到一些书籍数据有误,比如,"title": "Nitroservices"。通过一次写操作,它把数据修正成 "title": "Microservices",这个数据要发到领导者那里。然后,这个客户端要立即读取这个值,但是,这个读的请求到了追随者,也许这个追随者还没有更新。
This can be a common problem. For example, untill very recently Amazon S3 did not prevent this.
这可能是个常见的问题。比如,直到最近,Amazon 的 S3 也并没有完全阻止这个问题。
为了解决这个问题,每次写入时,服务器不仅存储新值,还有存储一个单调递增的版本戳。这个版本戳可以是高水位标记(High-Water Mark)或是混合时钟(Hybrid Clock)。然后,如果客户端希望稍后读取该值的话,它就把这个版本戳当做读取请求的一部分。如果读取请求到了追随者那里,它就会检查其存储的值,看它是等于或晚于请求的版本戳。如果不是,它就会等待,直到有了最新的版本,再返回该值。通过这种做法,这个客户端总会读取与它写入一直的值——这种做法通常称为“读自己写”的一致性。
请求流程如下所示。为了修正一个写错的值,"title": "Microservices" 写到了领导者。在返回给客户端的应答中,领导者返回版本 2。当客户端尝试读取 "title" 的值时,它会在请求中带上版本 2。接收到这个请求的追随者服务器会检查自己的版本号是否是最新的。因为追随者的版本号还是 1,它就会等待,知道从领导者那里获取那个版本。一旦获得匹配(更晚的)版本,它就完成这个读取请求,返回值 "Microservices"。

键值存储的代码如下所示。值得注意的是,追随者可能落后太多,或者已经与领导者失去连接。因此,它不会无限地等待。有一个配置的超时值,如果追随者无法在超时时间内得到更新,它会给客户端返回一个错误的应答。客户端之后尝试从其他追随者那里读取。
class ReplicatedKVStore…
Map<Integer, CompletableFuture> waitingRequests = new ConcurrentHashMap<>();
public CompletableFuture<Optional<String>> get(String key, int atVersion) {
if(this.server.serverRole() == ServerRole.FOLLOWING) {
//check if we have the version with us;
if (!isVersionUptoDate(atVersion)) {
//wait till we get the latest version.
CompletableFuture<Optional<String>> future = new CompletableFuture<>();
//Timeout if version does not progress to required version
//before followerWaitTimeout ms.
future.orTimeout(config.getFollowerWaitTimeoutMs(), TimeUnit.MILLISECONDS);
waitingRequests.put(atVersion, future);
return future;
}
}
return CompletableFuture.completedFuture(mvccStore.get(key, atVersion));
}
private boolean isVersionUptoDate(int atVersion) {
Optional<Integer> maxVersion = mvccStore.getMaxVersion();
return maxVersion.map(v -> v >= atVersion).orElse(false);
}一旦键值存储的内容前进到客户端请求的版本,它就可以给客户端发送应答了。
class ReplicatedKVStore…
private Response applyWalEntry(WALEntry walEntry) {
Command command = deserialize(walEntry);
if (command instanceof SetValueCommand) {
return applySetValueCommandsAndCompleteClientRequests((SetValueCommand) command);
}
throw new IllegalArgumentException("Unknown command type " + command);
}
private Response applySetValueCommandsAndCompleteClientRequests(SetValueCommand setValueCommand) {
getLogger().info("Setting key value " + setValueCommand);
version = version + 1;
mvccStore.put(new VersionedKey(setValueCommand.getKey(), version), setValueCommand.getValue());
completeWaitingFuturesIfFollower(version, setValueCommand.getValue());
Response response = Response.success(version);
return response;
}
private void completeWaitingFuturesIfFollower(int version, String value) {
CompletableFuture completableFuture = waitingRequests.remove(version);
if (completableFuture != null) {
completableFuture.complete(Optional.of(value));
}
}线性读
有时,读取请求需要获取最新的可用数据,复制的滞后是无法容忍的。在这种情况下,读取请求需要重定向到领导者。这是一个常见的设计问题,通常由一致性内核(Consistent Core)来解决。
示例
neo4j 允许建立因果集群(causal clusters)。每次写操作会返回一个书签,在读取副本上执行查询时会返回这个书签。这个书签会确保客户端总能获得写在书签处的值。
mongodb 会在其副本集中保持因果一致性(causal consistency)。写操作会返回一个操作时间(operationTime);这个时间会在随后的读请求中传递,以确保读请求能够返回这个读请求之前写入的数据。
cockroachdb 允许客户端从追随者服务器上进行读取。领导者服务器会在写操作完成之后发布最新的时间戳,称之为封闭时间戳(closed timestamps)。如果追随者在封闭的时间戳上有值,追随者就允许读取该值。
Kafka 允许消费来自追随者服务器的消息。追随者知道领导者的高水位标记(High-Water Mark)。在 Kafka 的设计中,追随者不会等待最新的更新,而是会给消费者返回 OFFSET_NOT_AVAILABLE 错误,期待消费者进行重试。